
What we built
We built a real-time AI fitness coach that can watch a user through the camera, track workout activity, count reps, monitor whether the user is in frame, and respond conversationally in real time. The goal was to create something that feels more like an active training partner than a passive app.
Why we built it
Most fitness apps feel static. They give routines or generic tips, but they do not feel present with the user during the workout itself. We wanted to explore whether a live multimodal agent could create a more responsive and engaging coaching experience.
How it works
The system combines live workout signals with a conversational agent. A vision layer interprets movement and workout state, then sends meaningful events into the application. Those events are used selectively so the agent can answer questions, track progress, and speak up at important moments without constantly interrupting the user.
How we used Google AI models
We used Google AI models, including Gemini Live, to power the real-time conversational experience. This gave the project a live agent layer that could respond naturally, handle dialogue in the moment, and support a more interactive coaching flow than traditional text-only systems.
We focused on conversational quality and timing, so the system feels like a coach that intervenes when useful rather than a narrator that talks constantly.
const event = getWorkoutEvent(visionSignal);
if (shouldIntervene(event, context)) {
await geminiLive.send({
type: 'coach_prompt',
payload: event
});
}How we used Google Cloud
We used Google Cloud as the foundation for hosting and supporting the application architecture. Google Cloud made it possible to organize the backend side of the project in a way that could support a real product rather than just a one-off demo.
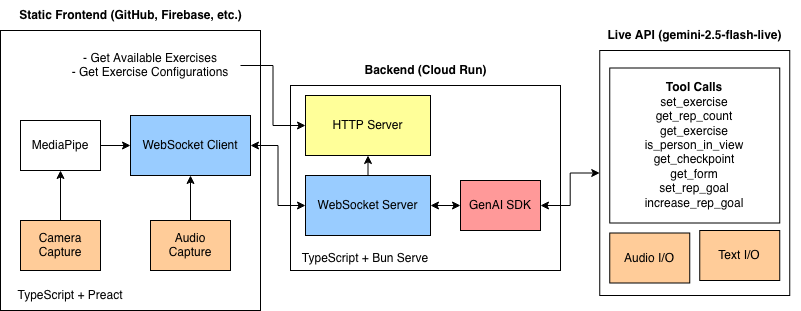
Key technical architecture
The architecture is event-driven. A vision and workout-tracking layer produces signals such as rep count, frame status, and form-related events. The application decides which events are worth sending into the live agent experience. Gemini Live handles the conversational layer, while the broader app logic manages thresholds, pacing, and when feedback should happen.
Camera + Motion Tracking -> Workout Events
Workout Events -> Decision Layer (thresholds + pacing)
Decision Layer -> Gemini Live Conversational Agent
Agent Output -> Voice/UI Coaching FeedbackBiggest challenges
The hardest problem was noisy live movement data. If the user moved out of frame or tracking became unstable, feeding every signal directly into the agent made the experience glitchy and distracting. We learned that more data is not always better in a live experience.
Lessons learned
A live agent feels smarter when it is selective. Timing, restraint, and signal quality mattered as much as raw AI capability.
The system became much better when we stopped trying to narrate everything and instead focused on only the most useful interventions.
Future improvements
We want to improve personalization, support more exercise types, make the coaching more adaptive over time, and refine the balance between user-requested feedback and automatic interventions. We also want to improve reliability across different environments and camera setups.
Demo / media
This section includes the final YouTube demo link and architecture diagram.
YouTube Demo
Architecture Graphic
Closing
This project was a strong example of how live multimodal AI can move beyond simple chat and start feeling like an interactive product experience. It also showed us that great real-time AI design is about control, timing, and user trust as much as model capability.
This post was created for the purposes of entering the Gemini Live Agent Challenge.